From Crikey:
Local bike paths mean higher house prices
That is one housing stimulus package I would be happy to see implemented. From the comments section:
More accurate take on alternate headline –
Bikeways found to be desirable trait amongst urban home buyers.
Temporary shortage of bikeways elevates prices in areas with bike paths.
Once all areas have bike paths, price distortion will be nil.
Captain Planet
Wednesday, May 4, 2011
Demand shocks – the details
Many pundits claim that increasing population increases demand. In technical economic jargon it shifts the curve to the right. But what we rarely see is an exploration of the two types of demand shock and the different potential price impacts.
The first type, as mentioned above, shifts the downward sloping demand curve to the right. This means there are more people with the same willingness to pay.
The second type is a shift of the demand curve up upwards. This represents a willingness to pay more for the same goods from the same number of people.
It’s pretty clear from this distinction which of these factors is in play in Australian housing.
 Let’s examine the first case. Consider an auction with 10 cars for sale and 50 bidders willing to pay $1000 for a car. You add another 50 people to the mix each also willing to pay $1000. If I’m not being clear enough, this is analogous to increasing population in the housing context.
Let’s examine the first case. Consider an auction with 10 cars for sale and 50 bidders willing to pay $1000 for a car. You add another 50 people to the mix each also willing to pay $1000. If I’m not being clear enough, this is analogous to increasing population in the housing context.
When the auction is run with the original 50 bidders each car sells for $1,000. When the auction is run with 100 bidders, the 10 cars still sell for $1,000 each.
This is an extreme scenario but does demonstrate a very real point. Unless the new potential buyers are willing to pay more for the same items as the existing buyers, the price won’t rise. At most, a second price auction (the result of an English open auction with heterogeneous preferences) becomes closer to a first price sealed bid auction by the addition of another bidder willing to bid at a price between the second and first price (read up on some auction theory here).
As I said before, new buyers, even a small cohort of the total market, can influence the price level if they are willing to pay more than the existing buyers, since prices are set at the margins. Imagine our car auction once again, and we give 10 of our original 50 bidders and extra $500 to spend on the car. What is the new result? All cars sell for $1500 each to these 10 bidders. Even though they were just 20% of the original market of buyers, they dragged the price up 50%. In fact even if there were thousands of buyers willing and able to pay $1000 for those 10 cars, the ten people willing to pay $1500 would always win.
Prices are set at the margin by those with the highest willingness to pay.
This example, where the demand curve is shifted vertically to reflect an increased willingness to pay by the same number of buyers, is shown graphically in the right hand side graph above.
But, you say, the key problem here is that supply is being overlooked - in the simplified examples demand curves are horizontal and there is no supply response. But look at the graphs again. Not only is the demand curve a more acceptable shape, but supply does respond in both circumstances. In the first, where the demand profile of buyers shifts horizontally supply does respond enabling prices to remain at their equilibrium level.
However, when the demand curve shifts vertically, it doesn’t matter how much supply responds to price increases, it cannot be a mechanism to bring prices back down (except under extreme assumptions about the shape of demand and supply and the limits of peoples willingness to pay at the top and bottom of the market).
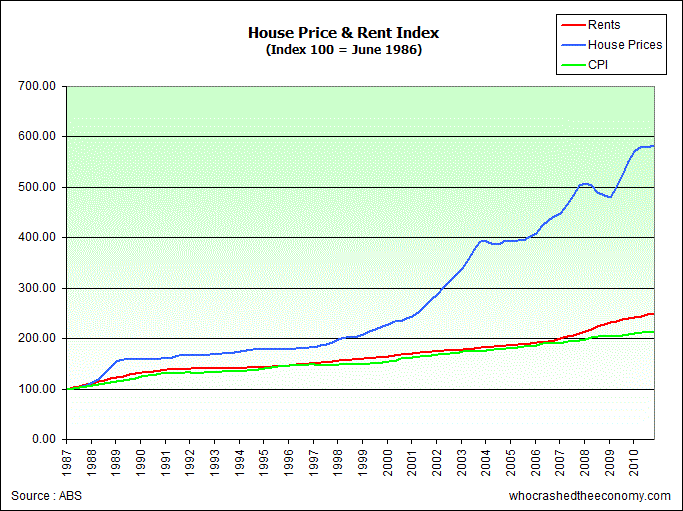
Of course, in the end this analysis is probably unecessary. The value of housing arises from the rents - its ability to generate revenue or provide a service. Since we haven’t seen rents outpace inflation significantly for any extended period in the past two decades, one must be quite certain that the cause of prices being much higher than a rational present value of future cash flows is pure demand side speculation.
The first type, as mentioned above, shifts the downward sloping demand curve to the right. This means there are more people with the same willingness to pay.
The second type is a shift of the demand curve up upwards. This represents a willingness to pay more for the same goods from the same number of people.
It’s pretty clear from this distinction which of these factors is in play in Australian housing.

When the auction is run with the original 50 bidders each car sells for $1,000. When the auction is run with 100 bidders, the 10 cars still sell for $1,000 each.
This is an extreme scenario but does demonstrate a very real point. Unless the new potential buyers are willing to pay more for the same items as the existing buyers, the price won’t rise. At most, a second price auction (the result of an English open auction with heterogeneous preferences) becomes closer to a first price sealed bid auction by the addition of another bidder willing to bid at a price between the second and first price (read up on some auction theory here).
As I said before, new buyers, even a small cohort of the total market, can influence the price level if they are willing to pay more than the existing buyers, since prices are set at the margins. Imagine our car auction once again, and we give 10 of our original 50 bidders and extra $500 to spend on the car. What is the new result? All cars sell for $1500 each to these 10 bidders. Even though they were just 20% of the original market of buyers, they dragged the price up 50%. In fact even if there were thousands of buyers willing and able to pay $1000 for those 10 cars, the ten people willing to pay $1500 would always win.
Prices are set at the margin by those with the highest willingness to pay.
This example, where the demand curve is shifted vertically to reflect an increased willingness to pay by the same number of buyers, is shown graphically in the right hand side graph above.
But, you say, the key problem here is that supply is being overlooked - in the simplified examples demand curves are horizontal and there is no supply response. But look at the graphs again. Not only is the demand curve a more acceptable shape, but supply does respond in both circumstances. In the first, where the demand profile of buyers shifts horizontally supply does respond enabling prices to remain at their equilibrium level.
However, when the demand curve shifts vertically, it doesn’t matter how much supply responds to price increases, it cannot be a mechanism to bring prices back down (except under extreme assumptions about the shape of demand and supply and the limits of peoples willingness to pay at the top and bottom of the market).
Of course, in the end this analysis is probably unecessary. The value of housing arises from the rents - its ability to generate revenue or provide a service. Since we haven’t seen rents outpace inflation significantly for any extended period in the past two decades, one must be quite certain that the cause of prices being much higher than a rational present value of future cash flows is pure demand side speculation.
Economics, Real Estate and the Supply of Land
As a general rule, economists relying on supply and demand curves without properly discussing the assumptions that sit underneath their graphs can be ignored.
Alan Evans' book Economics, Real Estate and the Supply of Land is an effort to refute Ricardian notions of land supply and rent, and offer an alternative neoclassical theory of land supply. The arguments in this book are taken by many who believe that reducing government involvement in town planning will decrease the price of housing. Evans’ reasoning is questionable to say the least, and supported by elaborate graphs with often biased assumptions and interpretations.
One of Evans’ aims is to refute the Ricardian proposition ‘that the price of land is high because the price of corn [read: houses] is high, and not vice versa’.
To do this he constructs a model economy with a fixed land supply where two agricultural uses compete for land – potatoes and corn. In the figure below we see his construction of this economy on the left, with demand for corn inverted so that the intersection of corn and potato demand determines the equilibrium share of land devoted to each crop, and the equilibrium rent of land at point A.
He then proceeds to add a demand shock to potatoes ‘for some reason’. The new blue line represents the new increased demand for potatoes which enables potato growers to bid up prices for land previously grown for corn and reduce the amount of land used to grow corn. He concludes with the following -
Now it is quite clear that the increase in the rent of land is not caused by the increase in the price of corn. Exactly the reverse is true. The price of corn has risen because the price of land has risen.
...
The rent for land is not solely determined by the demand for the product.
 His conclusions are wrong.
His conclusions are wrong.
First, it is still quite clear that at the new equilibrium the price of land for corn is still determined by the new higher price for corn. You could just as easily argue that every time a potato grower buys land from a corn grower he decreases the output of corn and the price of corn rises, thereby leading to an increase in the rents of land available for growing corn.
Second, he fails to notice that all he has done with the model is to demonstrate the inflation mechanism following an increase in money supply for one purpose. He increases total demand (potatoes plus corn) but shifts preferences towards potatoes so that corn demand is constant. The end result of his demand increase is to increase all prices in the model economy – potatoes, corn and rent.
Followers of Say would jump straight to this conclusion. You can’t simply increase total demand in the economy – demand is comprised of supply.
An actual demand shock, which models a change in preferences from corn to potatoes, is shown in the right hand side figure. You will notice that total demand remains constant and therefore the rents for this fixed quantity of land also remain constant.
So no, land rents do not determine prices. Prices determine rents.
Another example of poor reasoning is when Evans argues against a 100% land value tax. He argues that a tax of that nature would ‘freeze’ land development because there would be no incentive for a owner of agricultural land to sell his land to a developer for housing development, since he would not capture any of the value uplift. The rent achieved by the owner of the land will remain the same as when it is rented to the farmer – zero.
Yet in chapter 8 he argues that the value of land grows in anticipation of future higher value uses. In these cases, when the site is genuinely worth more as housing, the tax would be at a rate that reflects that higher value, and not the agricultural value. Therefore, the owner of the land will be facing a tax on the land value for housing while only receiving rents at agricultural values. As the city expands and the value of his land for housing surpasses the value for agriculture, he has a great incentive to sell or develop immediately to avoid losses.
Although I don’t support a 100% land value tax, I do support shifting the tax burden towards land and fixed rights to natural resources.
What we do learn from this book is that even the experts are prone to bias that affects their ability to apply objective logic and reason.
Alan Evans' book Economics, Real Estate and the Supply of Land is an effort to refute Ricardian notions of land supply and rent, and offer an alternative neoclassical theory of land supply. The arguments in this book are taken by many who believe that reducing government involvement in town planning will decrease the price of housing. Evans’ reasoning is questionable to say the least, and supported by elaborate graphs with often biased assumptions and interpretations.
One of Evans’ aims is to refute the Ricardian proposition ‘that the price of land is high because the price of corn [read: houses] is high, and not vice versa’.
To do this he constructs a model economy with a fixed land supply where two agricultural uses compete for land – potatoes and corn. In the figure below we see his construction of this economy on the left, with demand for corn inverted so that the intersection of corn and potato demand determines the equilibrium share of land devoted to each crop, and the equilibrium rent of land at point A.
He then proceeds to add a demand shock to potatoes ‘for some reason’. The new blue line represents the new increased demand for potatoes which enables potato growers to bid up prices for land previously grown for corn and reduce the amount of land used to grow corn. He concludes with the following -
Now it is quite clear that the increase in the rent of land is not caused by the increase in the price of corn. Exactly the reverse is true. The price of corn has risen because the price of land has risen.
...
The rent for land is not solely determined by the demand for the product.

First, it is still quite clear that at the new equilibrium the price of land for corn is still determined by the new higher price for corn. You could just as easily argue that every time a potato grower buys land from a corn grower he decreases the output of corn and the price of corn rises, thereby leading to an increase in the rents of land available for growing corn.
Second, he fails to notice that all he has done with the model is to demonstrate the inflation mechanism following an increase in money supply for one purpose. He increases total demand (potatoes plus corn) but shifts preferences towards potatoes so that corn demand is constant. The end result of his demand increase is to increase all prices in the model economy – potatoes, corn and rent.
Followers of Say would jump straight to this conclusion. You can’t simply increase total demand in the economy – demand is comprised of supply.
An actual demand shock, which models a change in preferences from corn to potatoes, is shown in the right hand side figure. You will notice that total demand remains constant and therefore the rents for this fixed quantity of land also remain constant.
So no, land rents do not determine prices. Prices determine rents.
Another example of poor reasoning is when Evans argues against a 100% land value tax. He argues that a tax of that nature would ‘freeze’ land development because there would be no incentive for a owner of agricultural land to sell his land to a developer for housing development, since he would not capture any of the value uplift. The rent achieved by the owner of the land will remain the same as when it is rented to the farmer – zero.
Yet in chapter 8 he argues that the value of land grows in anticipation of future higher value uses. In these cases, when the site is genuinely worth more as housing, the tax would be at a rate that reflects that higher value, and not the agricultural value. Therefore, the owner of the land will be facing a tax on the land value for housing while only receiving rents at agricultural values. As the city expands and the value of his land for housing surpasses the value for agriculture, he has a great incentive to sell or develop immediately to avoid losses.
Although I don’t support a 100% land value tax, I do support shifting the tax burden towards land and fixed rights to natural resources.
What we do learn from this book is that even the experts are prone to bias that affects their ability to apply objective logic and reason.
SOA, the User Interface Service Components, Apps, and Validation before Registering
System Architecture and the User Interface
In an article I wrote for The Northrop Grumman Technical Review Journal, entitled Service-oriented Architecture and User Interface Services: the Challenge of Building a User Interfaces in Services, I described five functional categories of user interfaces that a system architect might use to enable a user to employ for an SOA-based Composite Application. These included: Thin Client, Portal, Rich Client, Smart Client, and Rich/Smart Client. I describe the characteristics sub-functions of each such that a system architect be able to determine which would serve the Composite Application's user best.
In the article I linked the user interface categories to three categories of users (not my categories, but I could not track down the source), informational, transactional, and authoring. An informational user is one who uses data and information in an ad hoc (through search and discovery methods) or regularly to retrieve information from one or more sources. The data flow is primarily to the user. Many commercial cable companies set up their networks for this type of user; with data rates twice as fast to the customer of the data and to the supplier of the data. A transactional user is one who repetitiously inserts and/or retrieves the same type of data from an application. For example, the office administrator in a doctor's office makes appointments, that is, he or she looks up on a calendar for dates and times that are open and then inserts an appointment. For organizations, including businesses, the vast majority for the uses of data and user interfaces are of this type. Finally, there is the "authoring" use. This customer function is the most creative and would include: programming, document, video, and audio file creation and editing, engineering, verification and validation, and enumerable other content creation. Creating a user interface for the authoring category is the most complex because this service links to the most complex functions of an application.
There were two reasons for writing this article. First, for SOA-based Composite Applications, to demonstrate that the user interface could be built in Service Components, as there was a good deal of discussion between myself and my colleagues on this point. Second, to demonstrate the patterns that a System Architect can use in the activity of decomposing the customer's system requirements and deriving the functional requirements, which is a key step in the system architecture process.
In an article I wrote for The Northrop Grumman Technical Review Journal, entitled Service-oriented Architecture and User Interface Services: the Challenge of Building a User Interfaces in Services, I described five functional categories of user interfaces that a system architect might use to enable a user to employ for an SOA-based Composite Application. These included: Thin Client, Portal, Rich Client, Smart Client, and Rich/Smart Client. I describe the characteristics sub-functions of each such that a system architect be able to determine which would serve the Composite Application's user best.
In the article I linked the user interface categories to three categories of users (not my categories, but I could not track down the source), informational, transactional, and authoring. An informational user is one who uses data and information in an ad hoc (through search and discovery methods) or regularly to retrieve information from one or more sources. The data flow is primarily to the user. Many commercial cable companies set up their networks for this type of user; with data rates twice as fast to the customer of the data and to the supplier of the data. A transactional user is one who repetitiously inserts and/or retrieves the same type of data from an application. For example, the office administrator in a doctor's office makes appointments, that is, he or she looks up on a calendar for dates and times that are open and then inserts an appointment. For organizations, including businesses, the vast majority for the uses of data and user interfaces are of this type. Finally, there is the "authoring" use. This customer function is the most creative and would include: programming, document, video, and audio file creation and editing, engineering, verification and validation, and enumerable other content creation. Creating a user interface for the authoring category is the most complex because this service links to the most complex functions of an application.
There were two reasons for writing this article. First, for SOA-based Composite Applications, to demonstrate that the user interface could be built in Service Components, as there was a good deal of discussion between myself and my colleagues on this point. Second, to demonstrate the patterns that a System Architect can use in the activity of decomposing the customer's system requirements and deriving the functional requirements, which is a key step in the system architecture process.
An Example
While a functional design for the user interface Service Component may seem like a semi-useful abstraction, Apple seems to have intuitively understood the concepts very well. For those versed in SOA, an Apple "App" is simply a Service Component. It performs a single function or a small group of closely coupled functions (in a system architecture sense), for the user. Apple, and subsequently many other suppliers of wireless user interface devices, are now selling these User Interface Service Components. Most of them are for the informational user, if you can call streaming a movie informational--the functional concept is the same. Likewise stock quotes, news feeds, the weather radar real time image, the restaurants closest to the user (with customer critiques), and earth images of the user's current location (i.e. navigational maps) are all informational, that is, they are likely used on an as needed basis, or semi-regularly, to gain data and information about what is going on in the environment that affects them.
Even Apple's iTunes and Apps store are informational in that they link to discovery and download functions (services) on the server-side of the system. There are Apps, like playing music, games, and currently, the calendar, that are standalone applications (functions), but even the camera function (service) is loosely couple with the e-mail user interface Service Component. Consequently, the system architecture of the new mobile devices is, in fact, SOA-based, they just don't want to call it that.
As further proof, Apple is treating their Apps the manner a Service Component supplier should be treated. Apple has significant verification process to ensure that Apple's policies and standards are met, before the App is offered to customers. That is, Apple is verifying the Apps, the way all Service Component supplier should verify Service Components, especially, a user interface Service Component. These include meeting security and dependability standards, as well as having a Service Component Description. The Apps Store serves as the Service Component registry and discovery function in the SOA-based architecture.
Consequently, this is an excellent example of an SOA-based architecture (though it really doesn't use Web Services).
For more on SOA see SOA in a Rapid Implementation Environment, Enterprise SOA vs Ecosystem SOA, Private Cloud Computing vs Public Cloud Computing, Choreography vs Orchestration: Much Violent Agreement, and SOA Orchestration and Choreography Comparison. For more on System Architecture see SOA in a Rapid Implementation Environment, Enterprise Architecture and System Architecture, and Lean or Agile Enterprises and Architecture.
Even Apple's iTunes and Apps store are informational in that they link to discovery and download functions (services) on the server-side of the system. There are Apps, like playing music, games, and currently, the calendar, that are standalone applications (functions), but even the camera function (service) is loosely couple with the e-mail user interface Service Component. Consequently, the system architecture of the new mobile devices is, in fact, SOA-based, they just don't want to call it that.
As further proof, Apple is treating their Apps the manner a Service Component supplier should be treated. Apple has significant verification process to ensure that Apple's policies and standards are met, before the App is offered to customers. That is, Apple is verifying the Apps, the way all Service Component supplier should verify Service Components, especially, a user interface Service Component. These include meeting security and dependability standards, as well as having a Service Component Description. The Apps Store serves as the Service Component registry and discovery function in the SOA-based architecture.
Consequently, this is an excellent example of an SOA-based architecture (though it really doesn't use Web Services).
For more on SOA see SOA in a Rapid Implementation Environment, Enterprise SOA vs Ecosystem SOA, Private Cloud Computing vs Public Cloud Computing, Choreography vs Orchestration: Much Violent Agreement, and SOA Orchestration and Choreography Comparison. For more on System Architecture see SOA in a Rapid Implementation Environment, Enterprise Architecture and System Architecture, and Lean or Agile Enterprises and Architecture.
Friday, April 29, 2011
SOA in a Rapid Implementation Environment
"The farther backward you can look, the farther forward you can see. "
SOA is particularly well suited to Rapid Implementation and Rapid Transformation, which is an outgrowth of RAD Processes.
I've divided this post into two sections. First, a brief history of the trends in software coding and development, I've experienced; then, a discussion of how these trends will be amplified using Rapid Application Implementation processes, coupled with SOA.
Background
In my post The Generalized Agile Development and Implementation Process, I indicate that in my experience (that is over 40 years of experience (boy, time goes fast)), RAD software implementation process produces more effective and cost efficient software than any other method. There have been many changes in that time; binary to machine language, from machine languages to assemblers, from assemblers to procedural languages, from procedural languages to structured code, from structured code to object oriented languages, from object oriented to web services, which have been extended to service oriented.
Up to Object Oriented, all of these changes were developed to enhance the cost efficiency of creating and maintaining code. For example, going from coding in an assembler to coding in FORTRAN 1 enabled coders to construct an application much faster by using a single statement to insert a standard set of assembler code into the object deck of the application. For example, no longer did the coder have to rewrite all of the assembler instructions for saving data to given location on a disk--the instruction together with disk utilities took care of ensuring there was adequate space, writing the data, and the associated "housekeeping" activities. The downside to this change was that the object code was much larger, requiring more CPU cycles and memory. Consequently, there were (and are) applications that still require coding in an assembler (e.g., real time flight controls).
The second evolutionary transformation of coding was from procedural to structured. Due, simply, to the limitations in CPU cycles and memory in early computers and the programming culture of assembler where code was reused by branching into a section and then to another to minimize the number of separate instructions. With increasing computing power and the implementation of procedural languages, like FORTRAN and COBOL, the branching of code continued; to the point that maintenance of the code became infeasible in many cases, depending on the programmer. One way that many programmers, including me, used to avoid the issue way to use a modular IT system architecture--that is using callable subroutines as part of the code. In some cases the majority of the code was in subroutines with only the application work flow as part of the main--Sound familiar?
Anyway, this concept was formalized with the third evolutionary transformation, from procedural to structured (also known initially as Goto-less programming). This was a direct assault on programmers that used unconditional branching statements with great abandon. The thought here was to reduce the ball of tangle yarn logic found in many programs to increase the code readability and therefore maintainability. That's when I first heard the saying, "Intel giveth, structured programming taketh away", meaning that structured code use a great deal more computing power. At this point, compiler suppliers started to supply standardized sub-routine libraries as utilities (a current example of this type of library is Microsoft's Dynamic Link Library (DLLs)). Additionally, at this time Computer Aided Software Engineering (CASE) tools began to come on the market. These tools aided the code developer and attempted to manage the software configuration of the application.
The fourth transformation was from structure programming to object oriented development. Object Oriented Development (OOD) is not a natural evolution from structured programming. Instead, it's a paradigm shift in the programming concept--notice the shift in terminology from "programming" to "development". OOD owes as much to early simulation languages as coding. These languages, like Simscript, GPSS, GASP, all created models of "real-world" things (i.e., things with names or objects). Each of these model things was programmed (or parametrized) to mimic the salient characteristics of a "real-world" thing. OOD applied this concepts of objects with behaviors interfacing with each other to "real-world" software. So that, for example, a bank might have a class of objects called customers. Each object in the class represents one customer. The parametrize attributes of each customer object would include the customer's name, account number, address, and so on. Each of these customer objects has "behaviors" (methods) that mimic, enable and support what the customer wants and is allowed to do. For example, the customer object will have deposit, withdrawal, and inquiry methods. The interaction of the input and output methods, together with the objects and attributes, create the application.
A key problem in creating Object Oriented applications is with the interfaces between and among methods supporting the interaction among objects. OOD did not have standards for these interfaces so that sharing objects among applications was hit or miss. Much time and effort was spent in the 1990s on the integration among object orient application objects.
To resolve this interface, application developers applied the concepts of HTML so successfully use by web developers. HTML is based on the Standard Generalized Markup Language (SGML), developed, in part, by the aerospace industry and the Computer Aided Logistics Supporting initiative to support the inter-operation of the publishing of technical documentation. And this industry had a lot of it. At the time, (the late 1980s) a Grumman Corporation technical document specialist reported that when the documentation for all aircraft on an aircraft carrier was initially loaded on, the carrier sank 6". The SGML technical committee came up with standard tagging and standardized templates for document interchange and use. Web development teams latched on to the SGML concepts to enable transfer of content from the web server to the web browser.
Likewise, those seeking to easily interlink objects were looking for standardizing the interface and its description. The consequence of this process research was XML. The application of this standard to objects creates Web Service style Service Components. These components have a minimum of three characteristics that enable them to work as Web Service style Service Components:
- They persistent parametrized data mimicking the characteristics of some "real-world" object
- They have methods that create the object's behavior and
- They have interfaces adhering to the XML standard.
Having a great many Web Services is goodness, but it could turn the Internet into the electronic equivalent of a large library with no card catalog. The W3C and OASIS international standards organizations recognized this issue early and created to standards to help address the problem, Web Services Description Language (WSDL) and the Universal Description Discovery and Integration (UDDI). These standards, with many additional "minor" standards are converging on a solution to the "Electronic Card Catalog for Web Services" and/or the "Apps Store for Web Services".
In summary, initially programming was about creating code in as little space as possible. As hardware increased in power (according to Moore's Law), programming and its supporting tools focused on creating more cost effiecent code, that is, code that is easily to develop and maintain. This led to the paradigm shift of Object Oriented Development, which began to create code that enabled and supported particular process functions and activities. In total, this code was much more complex, requiring more CPU cycles, more memory, and more storage. Since, by the 1990s, the computing power had doubled and redoubled many times, this was not a problem, but linking the objects through non-standard interfaces was. The standards of Web Services provided the answer to this interfacing issue and created the requirements for another paradigm shift.
Now that Service Components (Web Services and Objects meeting other interface standards) can enable and support functions or activities of a process, organizations had a requirements for these functions to be optimally ordered and structured to support the most effective process possible, and the most cost efficient manner (as technology changed) and to be agile enough to enable the organization to successfully respond to unexpected challenges and opportunties.
In summary, initially programming was about creating code in as little space as possible. As hardware increased in power (according to Moore's Law), programming and its supporting tools focused on creating more cost effiecent code, that is, code that is easily to develop and maintain. This led to the paradigm shift of Object Oriented Development, which began to create code that enabled and supported particular process functions and activities. In total, this code was much more complex, requiring more CPU cycles, more memory, and more storage. Since, by the 1990s, the computing power had doubled and redoubled many times, this was not a problem, but linking the objects through non-standard interfaces was. The standards of Web Services provided the answer to this interfacing issue and created the requirements for another paradigm shift.
Now that Service Components (Web Services and Objects meeting other interface standards) can enable and support functions or activities of a process, organizations had a requirements for these functions to be optimally ordered and structured to support the most effective process possible, and the most cost efficient manner (as technology changed) and to be agile enough to enable the organization to successfully respond to unexpected challenges and opportunties.
Rapid, Agile, Assembly
Even a superb research library with a wonderful automated card catalog is of no value to anyone that has no idea what they are looking for. To use another analogy; my great uncle was an "inventor". But since he didn't what type of mechanical invention he might want to work on, he would go to auctions of mechanical parts--which meant that he had a shed sized room filled with boxes of mechanical part. He didn't know if he would ever use any of them, but he had them just in case.
Many organization's initial purchase of Service Components (Web Services) has been much like my uncle's acquisition of mechanical parts. Many times, the purchase of Service Components and supporting infrastructure components from multiple suppliers creates as many issues as it resolves because later versions and releases of "the standards" are incompatible with earlier versions of the same standard, and many software suppliers interpreting the standard to better match their existing products. The result is "the Wild West of Web Services" with supporters of one version of a standard or one product suite "gunning for" anyone that doesn't agree with them. However, the organization IT is cluttered with the equivalent of a Service Component bone yard (which is like an auto junkyard--a place where you can go to potentially find, otherwise difficult to locate car parts.
To convert these (Service Component) parts into Composite Applications supporting the organization's processes requires a blueprint in the form of a functional design (System Architecture), an identification of the design constraints on the process and tooling (including all applicable policies and standards). The key is the functional design and its implementation as a Composite Application using Assembly methods; see my posts Assembling Services: A Paradigm Shift in Creating and Maintaining Applications and SOA Orchestration and Choreography Comparison.
In addition to the paradigm shift from software development (coding) to Service Component assembly, there are two major changes in programming when moving from creating Web Services to creating SOA-based Composite Applications. If the processes for these are not well thought out, or have poor enabling and supporting training and tooling, or are poorly executed, then assembling Service Components will be difficult, time and resource consuming. This means the creating Composite Applications would be Slow Application Development (SAD???) instead of RAD. This happens frequently when initially operating the assembly process and seems to follow the axiom that "the first instance of a superior principle is always inferior to a mature example of an inferior principle". However, many books on the development of SOA-based applications describe processes that either are inherently heavy weight and slow and resources consuming, or that will process applications with a great many defects; and rectifying a defect in a product that is being used costs much more than rectifying it in design. Therefore, spending the time and effort to fully develop the process and will continue to provide a genuine ROI with each use of the process--though the ROI is difficult to measure unless you've already have a poor process that measure first, or if you can measure the ROI in a simulation of alternatives.
Here is an outline of the RAD-like implementation process I would recommend. It fits very nicely within The Generalized Agile Development and Implementation Process I discussed. Implementing and operating/ maintaining a SOA-based Composite Application is much more than simply coding into a work flow Service Component and then executing it in production. There are several activities required to implement or transform a Composite Application in an effective and cost efficient manner using a RAD-like implementation process.
This implementation process is predicated on at least 5 items in the organization's supporting infrastructure.
- That the implementation team has established or is establishing an Asset and Enterprise Architecture Repository (AEAR). This should include a Requirements Identification and Management system and repository (where all of the verification and validation (tests) are stored).
- That the implementation team is using a CMMI Level 3 conformant process (with all associated documentation
- That there are business process analysis (including requirements identification and modeling), and a RAD-like Systems Engineering and System Architecture process preceding the implementation process.
- That the implementation team has access to a reasonable set of Composite Applications modeling tools that link to data in the AEAR.
- That the organization's policies and standards are mapped into automated business rules that the process flow can use through a rules engine linked to both the Orchestration engine and the Choreography engine.
First, create and model the process or work flow of the Composite Application before assembling the Service Components. The key technical differentiator of an SOA-based application from a web service or other type of application is that there are three distinct elements of the SOA application; the work flow, the Service Components (that support the activities and functions of the process), and the business rules that are derived from the organization's policies and standards. This first activity creates the process flow and ensures that all applicable business rules are linked to the flow in the correct manner.
For those Composite Applications using Orchestration, the entire Composite Application should be statically and dynamically modeled to verify the functions using Service Components models to ensure that they are in proper order, that their interfaces are compatible, that they meet all design constraints, that the Composite Application will meet all organization's business rules (that automate the organization's internal and external policies and standards, and that the Composite Application's performance and dependability meet their requirements.
I found that with RAD, performing this type of verification activity can take from 1 hour for simple applications to two days for a complex application with complete regression testing. Additionally, I found that both software coders/programmers and program management wanted to skip all of the verification activities that I recommended, but for somewhat different reasons.
The reason for developers not wanting to do it, was, according to them, "Boring"; actually, it is more "programmer friendly", that is, to ignore verifying that the requirements have been met and that there are no induced defects (defects introduced in the process of updating the Composite Application's functionality), which required in a RAD process to ensure reliability. Additionally, it's more fun to program than it is to ensure that the version verified is the version that goes into production.
The reason why program managers don't pay attention to the customer's requirements and the requirements verification is that the earned value procedures--the supposed measurement of a program's progress--is not based on measuring how many of the customer's system requirements have been met through verification and validation (V&V), but on the resource usage (cost and schedule) versus the implementer's best guess at how much of which task in the "waterfall" schedule have been completed. Since producing the earned value is the base for payment by the customer and the PM's and management's bonuses, that is what they focus on--naturally. Therefore, neither the implementers or management have any inducement to pay a great deal of attention to ensuring that the customer's requirements are met.
However, with a good RAD process like the Generalized Application Development and Implementation Process, the customer's system requirements are paramount (additionally, my experience has been focusing on the programmatic requirements (cost and schedule) pushes the schedule to the right (it takes longer), while focusing on ensuring the customer's requirements (functions, and design constraints) are met, pushes the schedule to the left).
Assemble the Composite Application and Verify
Second, once the work flow has been verified, then it is time to link the Service Components to it in the development environment. The verification, in this case, is to assure that the Service Component behaviors are as expected (the components meet the component requirements), and that the components have the expected interfaces.
Verify the Sub-systems
Third, once components have been assembled into a portion of the system, or a sub-system, these too, must be verified to ensure that they enable and support the functions allocated to them from the System Architecture (functional design) and meet all applicable design constraints. Again, this can be done in the development environment, and must be under configuration control.
System Validation
Fourth, System Validation means that the current version is evaluated against the customer's system requirements, that is, that it performs as the customer expects, with the dependability that the customer expects, and meets all of the policies and standards of the organization (as embodied in the design constraints). Typically, this step is performed in a staging environment. The are several reasons for doing this, as most configuration management training manuals discuss. Among these are:
- Separating the candidate application from the developers, since the developers have a tendency to "play" with the code, wanting to tweak it for many different reasons. These "tweaks" can introduce defects into code that has already been through the validation process. Migrating the code from the development environment to the staging environment and not allowing developers access to the staging environment, can effectively lock out any tweaking.
- The migrating the application to the staging environment, itself, can help to ensure the migration documentation is accurate and complete. For example, the order in which code patches are applied to their COTS product can change, significantly, the behavior of the product.
- The staging environment is normally configured in a manner identical with the production environment. It uses the same hardware and software configurations, though from large installation, the size of the systems is generally smaller than production. Since the code or product implementers have a tendency to "diddle with" the development environment. Very often I've been part of efforts where the code runs in the development/assembly environment, but not production because the configuration of the two environments is very different with different releases of operating system and data base COTS software. Having the staging environment configuration control to match the production environment obviates this problem.
Roll-out
Fifth, Roll out consists of releasing the first or Initial Operating Capability (IOC) or the next version of the Composite Application. In the RAD or Rapid Application Implementation process, this may occur every month to 3 months. If all of the preceding activities have been successfully execute, post roll out stablization will be very boring.
Advantages of SOA in a RAD/I Process
There are several advantages to using SOA in a Rapid Application Development/Implementation process including:
There are several advantages to using SOA in a Rapid Application Development/Implementation process including:
- The implementer can use Service Component or assemble a small group of Service Components to perform the function of a single Use Case. This simplifies the implementation process and lends itself to short-cycle roll-outs.
- Since the Service Components are relatively small chunks of code (and generally perform a single function or a group of closely coupled functions) it allows the implementers at least the following actions:
- Replace one Service Component with another technologically updated component without touching the rest of the Composite Application as long as the updated component has the same interfaces as the original. For example, if a new developmental authentication policy is set
- Refactoring and combining the Service Components is simplified, since only small portions of the code are touched.
- Integration of COTS components with components that are create for/by the organization (for competitive advantage) is simplified. While my expectation is that 90 percent or more of the time, assembling COTS components and configuring their parameters will create process enabling and supports Composite Applications, there are times when the organization's competitive advantage rests on a unique process, procedure, function, or method. In these cases unique Service Components must be developed--these are high-value knowledge-value creating components. It's nice to be able to assemble these with COTS components in a simple manner.
- The Structure of an SOA-based Composite Application has three categories of components: Service Components, Process or Workflow Components, and the Business Rules. Change any of these and the Composite Application changes. Two examples:
- Reordering the functions is simplified because it requires a change in the process/workflow component rather than a re-coding of the entire application.
- If properly created in the AEAR, when an organization's policy or standard changes, the business rules will reflect those changes quickly. Since in well architected SOA-based systems will have a rules engine tied to the rules repository in the AEAR and to the orchestration and choreography engines executing the process or work flows, any change in the rules will be immediately reflected in any Composite Application using the rule.
These two example demonstrate that a Composite Application can be changed by changing the ordering or rules imposed on the application, without ever write or revising any code. This is the reason that SOA is so agile, and another reason it works so well with short-cycle Rapid Application Development and Implementation processes.
Tooling
In addition to good training on a well thought out Rapid Application Development and Implementation process, the implementation of the process for creating SOA-based Composite Applications requires good tools and a well architected AEAR. While implementing the process and acquiring the tooling and instantiating the AEAR may seem like it's a major cost risk, it really doesn't need to be, (see my post, Initially Implementing the Asset and Enterprise Architecture Process and an AEAR). Currently, IBM, Microsoft and others have tooling that can be used "out of the box" or with some tailoring to enable and support the development and implementation environment that is envisioned in this post. Additionally, I have used DOORS, SLATE, CORE Requisite-Pro, and other requirements management tools on various efforts and can see that they can be tailored to support this process Rapid Appliction Development and Implementation process.
However, as indicated by the Superiority Principle, it will take time, effort, and resources to create the training and tooling, but the pay back should be enormuous. I base this prediction on my experience with the RAD process that I developed in 2000, which by 2005 had been used on well over 200 software development efforts and which was significantly increasing the process effectiveness of the IT tools supporting the process, and the cost efficiency of the implementations.
(PS--the Superiority Principle is "The first instance of a superior system is always inferior to a mature example of an inferior system").
However, as indicated by the Superiority Principle, it will take time, effort, and resources to create the training and tooling, but the pay back should be enormuous. I base this prediction on my experience with the RAD process that I developed in 2000, which by 2005 had been used on well over 200 software development efforts and which was significantly increasing the process effectiveness of the IT tools supporting the process, and the cost efficiency of the implementations.
(PS--the Superiority Principle is "The first instance of a superior system is always inferior to a mature example of an inferior system").
Thursday, April 28, 2011
Faulty Reasoning
I’ve come across some fine examples of faulty reasoning lately in two key areas.
1. Analysing the economic importance of declining environmental quality, and
2. Assessing the impact of price drops in the Australian property market.
So let us take a closer look.
Pro-urban sprawl advocates (I didn’t really know there were so many until just recently) try to shrug off the claim of deterimental impacts on agricultural production from urban sprawl due to irreversibly land use changes. For example –
Suburban Development is not destroying farmland. Smart growth activists claim farmland is disappearing at dangerous rates and that government needs to protect farmland lest we lose the ability to feed ourselves. As growth expert Julian Simon wrote, this claim is "the most conclusively discredited environmental-political fraud of recent times." United States Department of Agriculture data show that from 1945 to 1992 cropland area remained constant at 24 percent of the United States. Though urban land uses increased, they now account for only 3 percent of the land area of the United States. Today, American farmers produce more food per acre than ever before. In fact, the number of acres used for crops peaked in 1930, but because of the ingenuity and innovation of American farmers, the United States continues to produce more food on less land. (here)
Why is this argument based on faulty reasoning?
(As an aside, I would say that most smart growth advocates are not so extreme as to suggest that sprawl will destroy our ability to feed ourselves, just that sprawl makes it more difficult to produce the same quantity food that would otherwise be the case).
The faulty reasoning occurs because Simon compares the past situation with the present situation. He does not compare the present situation to the alternative present situation where urban sprawl did not replace some of the most highly productive agricultural land.
To be clear three scenarios are as follows.
a) 1945 levels of agricultural productivity with 1945 area of land under production.
b) 1992 levels of agricultural productivity with 1945 area of land under production, less land lost to sprawl, plus marginal land brought under production.
c) 1992 level of agricultural productivity with 1945 area of land under production plus marginal land brought under production.
Simon compares a) and b), not b) and c) which would reveal the true impact of sprawl on agricultural production. Just because we are now more productive, doesn’t mean that losing some of the better agricultural land is not important.
To apply Simon’s argument in another context, he would argue that having my car stolen today does not matter because I will still be wealthier in ten years than I am today, therefore I should not bother protecting my car from being stolen. It’s absurd. He should compare my wealth in ten years under the stolen and not stolen scenarios.
This same faulty reasoning can be found in many discussions on environmental policy.
The second area where faulty reasoning gets plenty of air time comes from overlooking that financial leverage works in reverse. This is why small percentage drops in housing prices have major impacts on the household balance sheet.
As an example, consider the following comment -
Why is it that when the stock market falls 2.1 per cent in a day it hardly makes the news, yet when property prices fall by the same amount over a three month period, considering that the median price rose by 160 per cent over a ten year period, it is a slump?
The property industry needs to stop with its hysteria (here)
Okay then, let’s just see.
For the leveraged investor small falls in value are very bad news. Say they borrowed $80,000 to buy a $100,000 home with annual costs of $1,500 and annual rental income of $5,000. Interest costs on the loan are $6,000, so the investor makes an annual loss $2,500/year (2.5%). If prices increase 10% over two years, they cash out with $110,000, and subtracting their $5,000 of losses, gives them a $5,000 return on the original $20,000 invested, or a 12% annualised return on equity.
But if prices instead fall by just 5% over those two years the story is very different.
They sell the home for $95,000, repay the $80,000 loan, but have also lost $5,000 in the two years from negative gearing. This leaves them with just $10,000 of their initial $20,000 deposit. That’s a 22% annualised loss over two years. In other words THEY LOST 50% OF THEIR CASH! Remember this when you look at today’s housing data – home values in Brisbane and Perth are both down more than 6% over the past year.
If prices fall just 15% over two years the 80% leveraged investor makes a 100% loss on their equity.
(There is much more detail to examine here, including tax benefits of negative gearing, opportunity cost of the deposit, transaction costs and so on. But the principle stands.)
So yes, small falls in home values have a very serious effect on the balance sheet of homes due to leverage. It is the same reason that small gains had such a great positive benefit and why a few years of 10% plus growth made us all very wealthy in the short term.
1. Analysing the economic importance of declining environmental quality, and
2. Assessing the impact of price drops in the Australian property market.
So let us take a closer look.
Pro-urban sprawl advocates (I didn’t really know there were so many until just recently) try to shrug off the claim of deterimental impacts on agricultural production from urban sprawl due to irreversibly land use changes. For example –
Suburban Development is not destroying farmland. Smart growth activists claim farmland is disappearing at dangerous rates and that government needs to protect farmland lest we lose the ability to feed ourselves. As growth expert Julian Simon wrote, this claim is "the most conclusively discredited environmental-political fraud of recent times." United States Department of Agriculture data show that from 1945 to 1992 cropland area remained constant at 24 percent of the United States. Though urban land uses increased, they now account for only 3 percent of the land area of the United States. Today, American farmers produce more food per acre than ever before. In fact, the number of acres used for crops peaked in 1930, but because of the ingenuity and innovation of American farmers, the United States continues to produce more food on less land. (here)
Why is this argument based on faulty reasoning?
(As an aside, I would say that most smart growth advocates are not so extreme as to suggest that sprawl will destroy our ability to feed ourselves, just that sprawl makes it more difficult to produce the same quantity food that would otherwise be the case).
The faulty reasoning occurs because Simon compares the past situation with the present situation. He does not compare the present situation to the alternative present situation where urban sprawl did not replace some of the most highly productive agricultural land.
To be clear three scenarios are as follows.
a) 1945 levels of agricultural productivity with 1945 area of land under production.
b) 1992 levels of agricultural productivity with 1945 area of land under production, less land lost to sprawl, plus marginal land brought under production.
c) 1992 level of agricultural productivity with 1945 area of land under production plus marginal land brought under production.
Simon compares a) and b), not b) and c) which would reveal the true impact of sprawl on agricultural production. Just because we are now more productive, doesn’t mean that losing some of the better agricultural land is not important.
To apply Simon’s argument in another context, he would argue that having my car stolen today does not matter because I will still be wealthier in ten years than I am today, therefore I should not bother protecting my car from being stolen. It’s absurd. He should compare my wealth in ten years under the stolen and not stolen scenarios.
This same faulty reasoning can be found in many discussions on environmental policy.
The second area where faulty reasoning gets plenty of air time comes from overlooking that financial leverage works in reverse. This is why small percentage drops in housing prices have major impacts on the household balance sheet.
As an example, consider the following comment -
Why is it that when the stock market falls 2.1 per cent in a day it hardly makes the news, yet when property prices fall by the same amount over a three month period, considering that the median price rose by 160 per cent over a ten year period, it is a slump?
The property industry needs to stop with its hysteria (here)
Okay then, let’s just see.
For the leveraged investor small falls in value are very bad news. Say they borrowed $80,000 to buy a $100,000 home with annual costs of $1,500 and annual rental income of $5,000. Interest costs on the loan are $6,000, so the investor makes an annual loss $2,500/year (2.5%). If prices increase 10% over two years, they cash out with $110,000, and subtracting their $5,000 of losses, gives them a $5,000 return on the original $20,000 invested, or a 12% annualised return on equity.
But if prices instead fall by just 5% over those two years the story is very different.
They sell the home for $95,000, repay the $80,000 loan, but have also lost $5,000 in the two years from negative gearing. This leaves them with just $10,000 of their initial $20,000 deposit. That’s a 22% annualised loss over two years. In other words THEY LOST 50% OF THEIR CASH! Remember this when you look at today’s housing data – home values in Brisbane and Perth are both down more than 6% over the past year.
If prices fall just 15% over two years the 80% leveraged investor makes a 100% loss on their equity.
(There is much more detail to examine here, including tax benefits of negative gearing, opportunity cost of the deposit, transaction costs and so on. But the principle stands.)
So yes, small falls in home values have a very serious effect on the balance sheet of homes due to leverage. It is the same reason that small gains had such a great positive benefit and why a few years of 10% plus growth made us all very wealthy in the short term.

Subscribe to:
Posts (Atom)